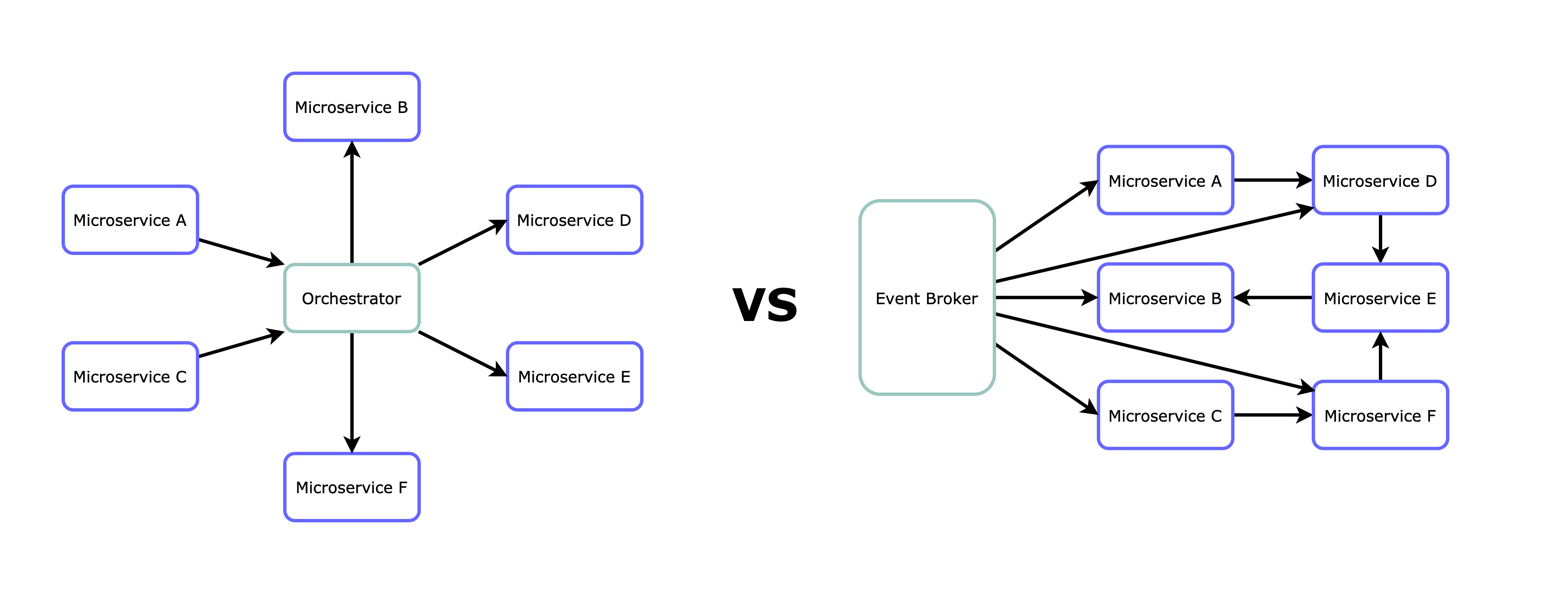
So you want to build microservices, you have identified the properly isolated domains and boundaries for each one of them and now it’s time to find out how to make them interact with each other… Now is when you ask yourself, should we use an orchestrator approach? a choreography approach? mmmm, maybe a hybrid solution?
In this post, I’m going to talk about the different microservices architectures, and I will try to answer those questions, so when you have to make the call you have at least an idea of what are the tradeoffs of each one.
The orchestrator architecture
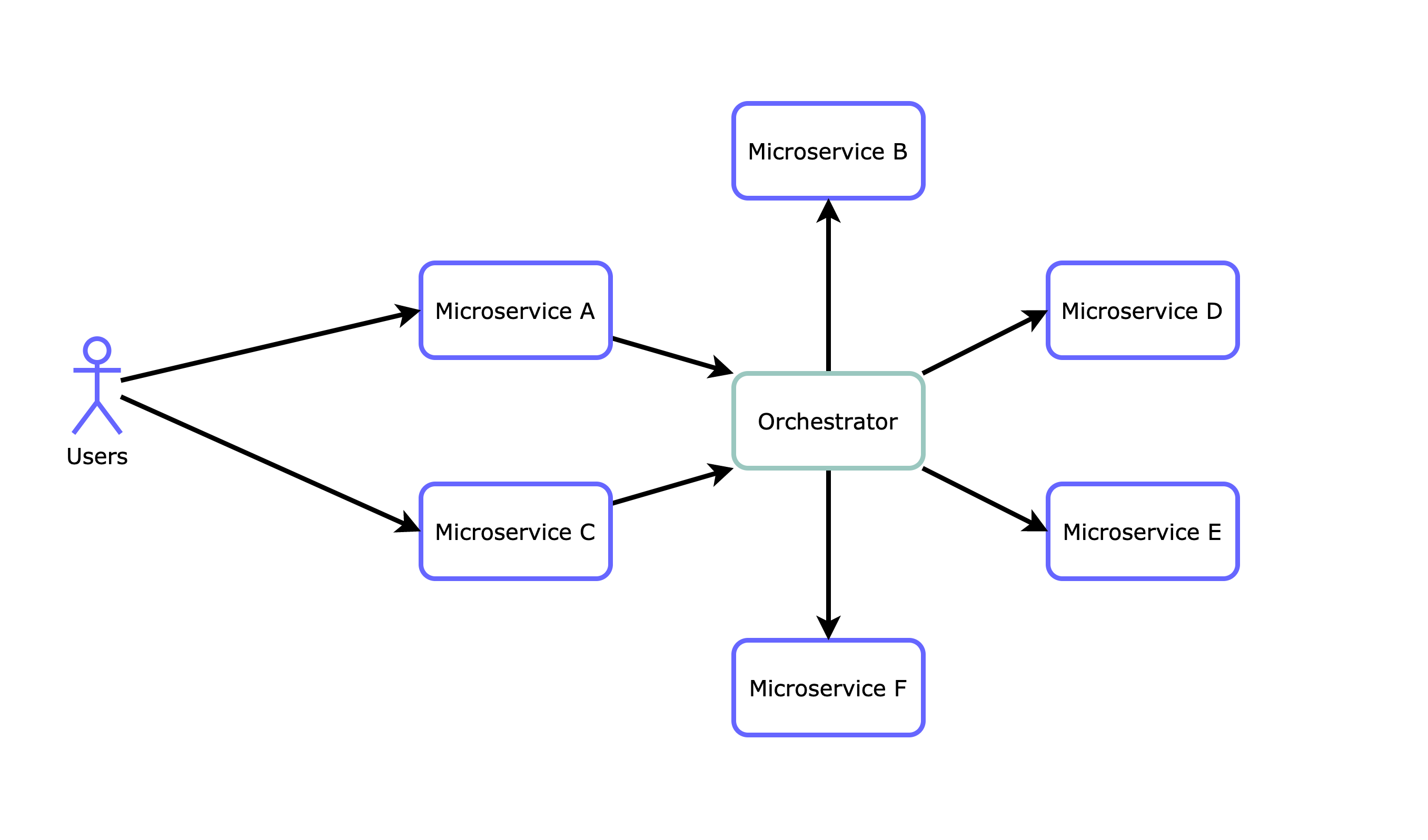
On the orchestrator architecture, our users will probably hit an api-gateway, which will then trigger an event on the orchestrator. Now the orchestrator service is in charge of executing the business logic by making requests to the other microservices while keeping track of the event status. It is a centralized controller and the requests are often synchronous.
Let’s dive into the pros and cons of the orchestrator approach:
Pros
- Business logic is “hardcoded” and tangible
- Easy request flow and status tracking
Cons
- Tightly coupled services. Dependencies
- Single point of failure
The choreography architecture
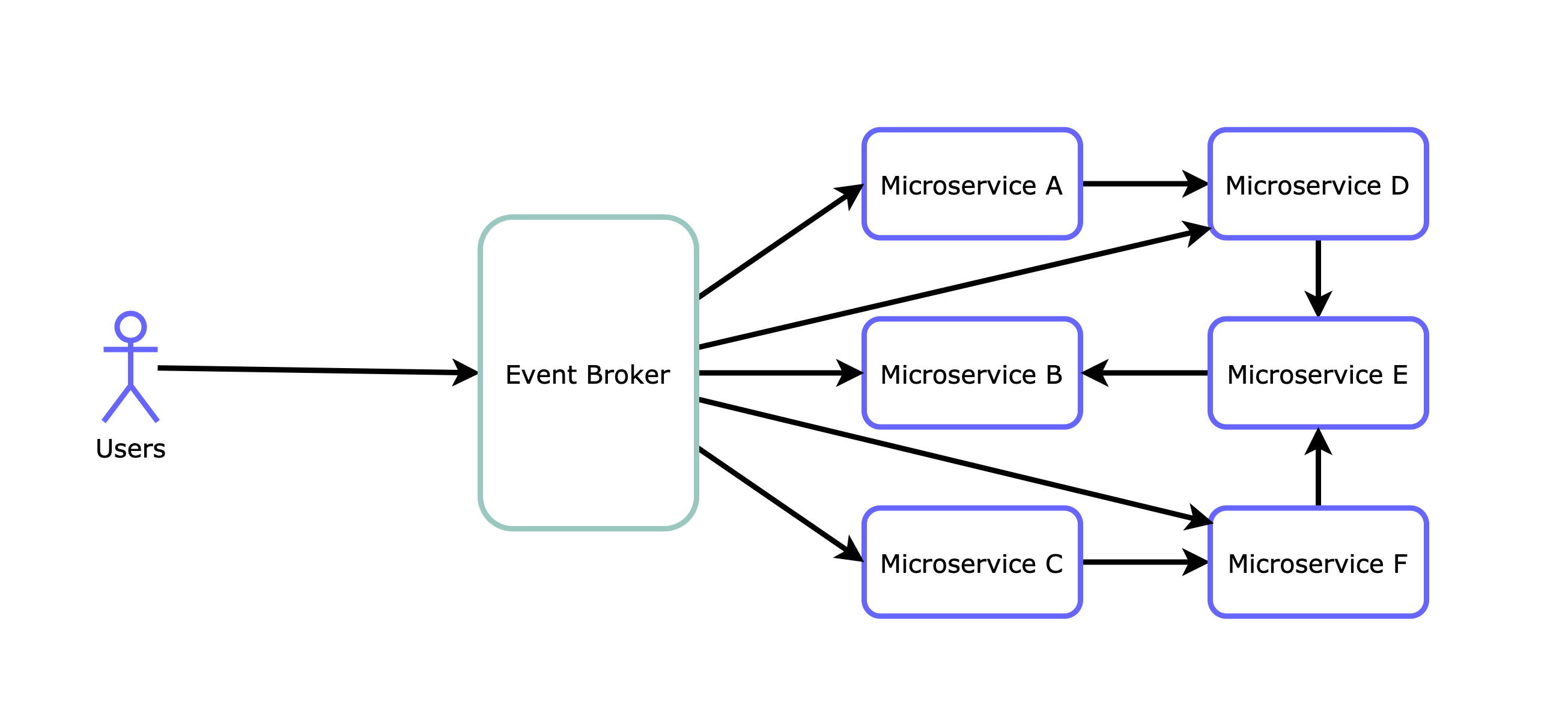
The choreography architecture, often called message broker or reactive architecture is, reactive and loosely coupled. Here, a message/event broker receives the requests and the microservices subscribe to them. Each one of them triggers when a certain message appears in the broker. If needed, after a service is triggered by a message it can also talk to other services directly, to chain different flows. Messaging is asynchronous here, with a publisher/subscriber pattern.
It has some advantages over the orchestrator architecture, but it comes with other problems, let’s dive into them:
Pros
- Loosely coupled services
- Isolated, independent packages of services
- No single point of failure
Cons
- Monitoring and observability are quite complex
- Difficult request flow control (timeouts, retries, errors)
- End-to-end knowledge of the system, where is the business logic?
Benefits and tradeoffs of both approaches
A typical tradeoff of the orchestrator approach is that you have tightly coupled services, on this topic, the choreography approach is the clear winner.
The single-point-of-failure vs no-point-of-failure would score another point for the choreography architecture, yet it is something that can be solved with the underlying cloud architecture and some good programming skills. So, no clear winner here.
Monitoring, observability, and flow control are big benefits for the orchestrator approach, so it is the clear winner. Something simple like setting up a timeout for a request is a pain to do in the choreography architecture and don’t try to find out where your system is failing on a choreography architecture, it is a nightmare if you haven’t spent a lot of time on properly monitoring the system.
However, there are other benefits and tradeoffs that are almost never mentioned…
On an orchestrator architecture, the orchestrator itself contains the business logic. It is there. You can read the actual code. On the other hand, on the choreography architecture, you have to read a document or see a graphic, because only a few people really know the whole end-to-end architecture. This becomes an issue when for example, someone leaves the company, understanding end-to-end complex choreographies can be really a problem.
The choreography approach is often a popular choice done by “cloud-native architects”. This is because most cloud providers have some really good event/messaging systems and there are a lot of tools with buzzwords names that support it. However, for developers, (yes, those that will actually write the code) thinking about a system asynchronously is quite difficult and it means an important mind shift.
The hybrid approach
With all these benefits and tradeoffs of both architectures, there is no clear standard path to choose. Both have their own pros and cons, and the tradeoffs of each approach are different. But if you look closer, they kind of complement each other. If we could have a mix of the benefits from the orchestrator approach and the choreography approach, it would be ideal!
Enters the hybrid approach, and there are many ways you can implement a mix of both architectures, but let’s focus on the next example:
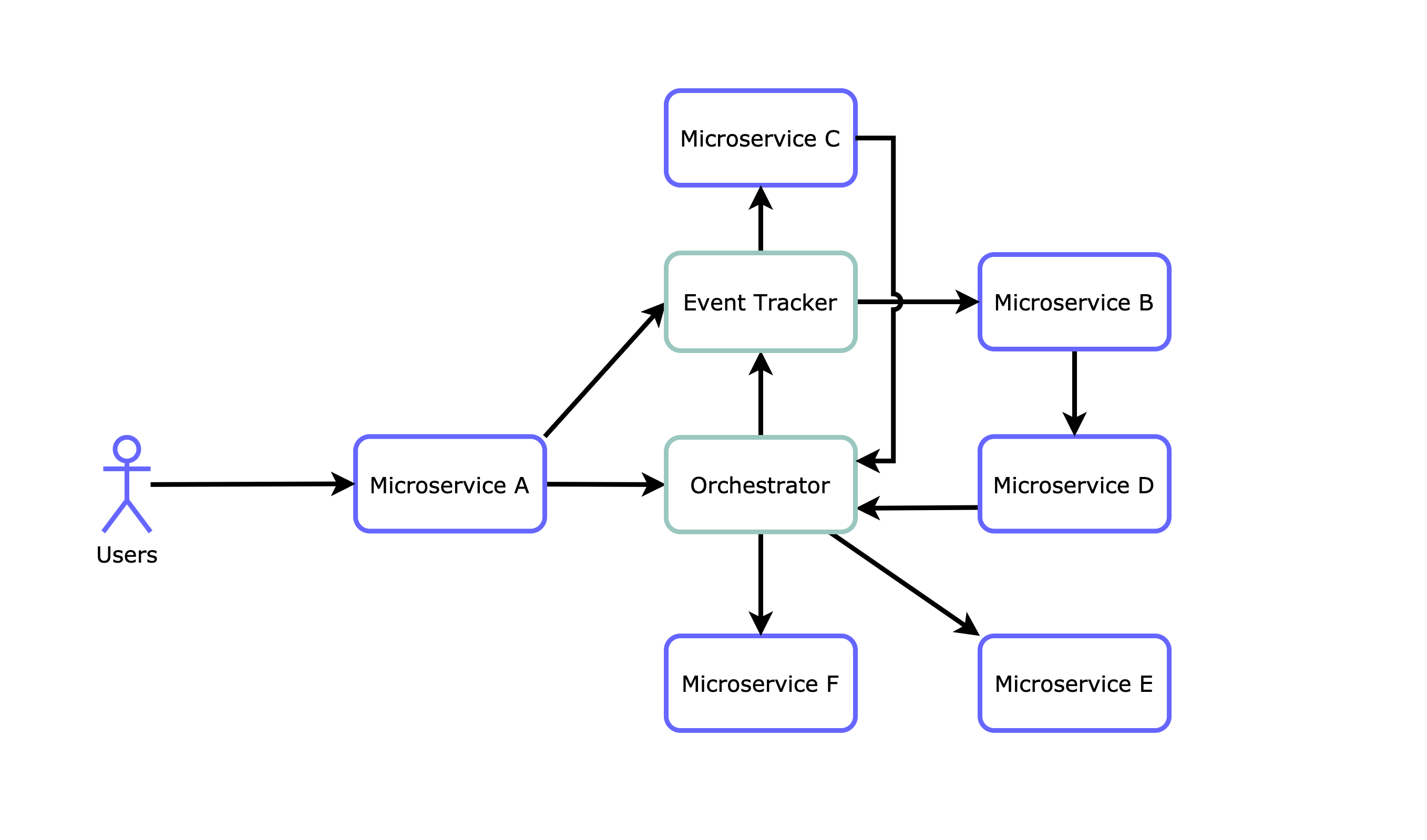
On the hybrid architecture, we combine the two things, an orchestrator and an event tracker. The requests are received by both and the orchestrator starts to execute the business logic but keeping track of the request in sync with the event tracker. This allows the microservice C, B, and D to do decoupled things, based on the event subscription/status, while the orchestrator still orchestrates what happens with the whole flow and directly controls microservices E and F.
With this mix, we can have tightly coupled services when sequentiality is needed, and loosely coupled services when we need to do parallel things “in the background”
When to use each one?
The orchestrator approach is good when you have a business-critical sequential flow. There, the orchestrator can handle the “what if” cases. For example, if one microservice needs to return successfully before calling a second microservice.
The choreography approach is good when you need to do a lot of things in parallel, it allows you to have faster processing times and it scales easily. For example, job processing in the background
The hybrid approach is more flexible, here you can have parallel asynchronous processing while still keeping track of the business logic when it is needed. For example, job processing in the background, but only after a logic sequence of services has been addressed.
Conclusion
Whatever approach you decide to follow, take it as a guide, but not be limited to it.
There are perfectly fit use-cases for each approach, no one is better than the other, I prefer the hybrid approach because of its flexibility.