In this post, I want to show you two different cloud architectures for multi-tenancy. It doesn’t matter if you are planning to have a SaaS product with millions of tenants or just a handful of them, it is important to think about the pros and cons of the different models.
We will discuss the simplified cloud infrastructure architecture, not the code. Should you have separate databases? replicate workloads? a different load-balancer?
Let’s answer all those questions.
Multi-User vs Multi-Tenant. What do we mean by multi-tenancy?
A quick google search shows a lot of different answers for that question, so let’s clarify what we will be covering in this post.
When we say multi-tenant we refer to a software architecture designed in such a manner that it can serve multiple users, grouped in tenants. Not only a multi-user SaaS app.
For example, a software whose customers are companies, and the users are the companies employees.
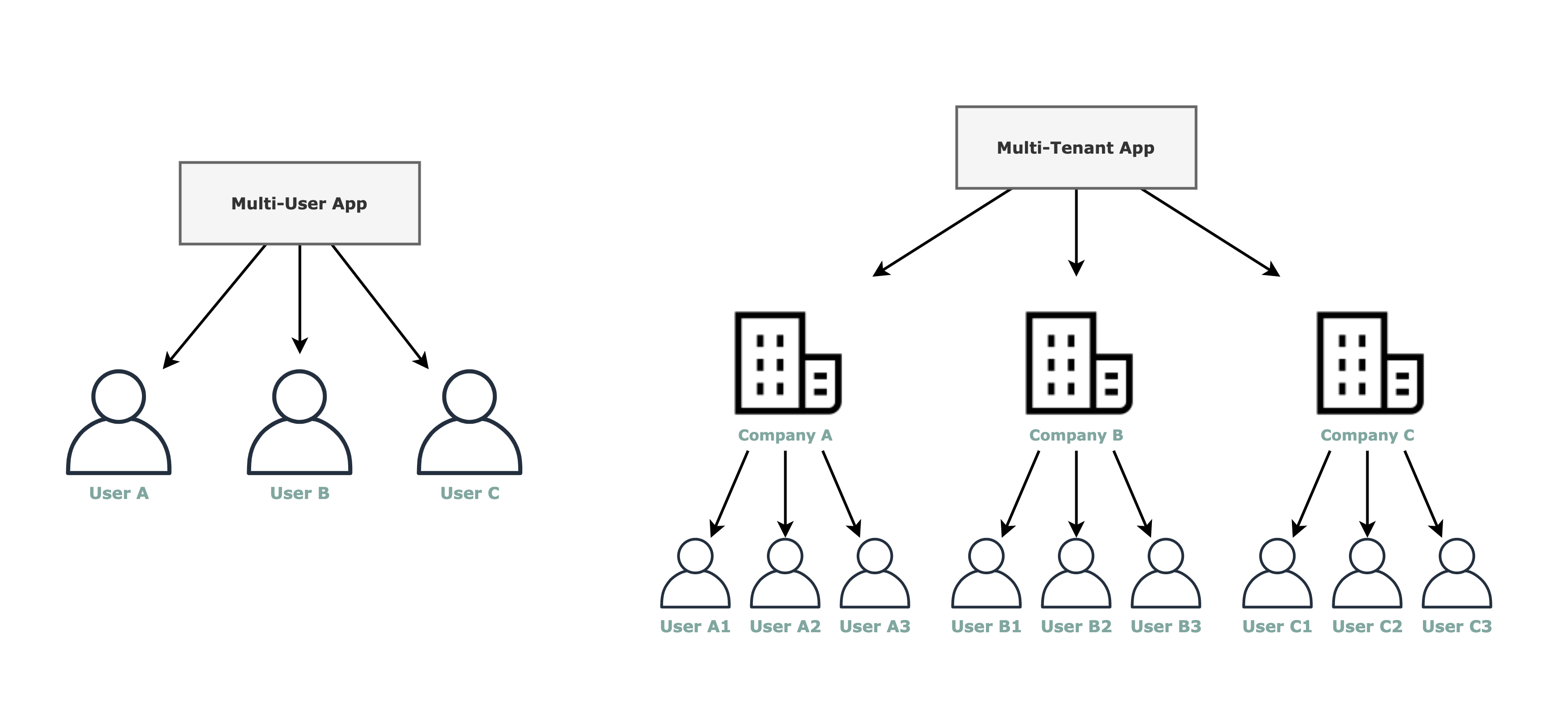
In this post, we will be focusing on the multi-tenant architectures, not the multi-user ones. Therefore the analysis is going to be focused on 4 items:
- Ingress
- Backend
- Data
- Cloud Infra and Security
- Product compatibility. When to choose each one?
Architecture #1: tenant aware app
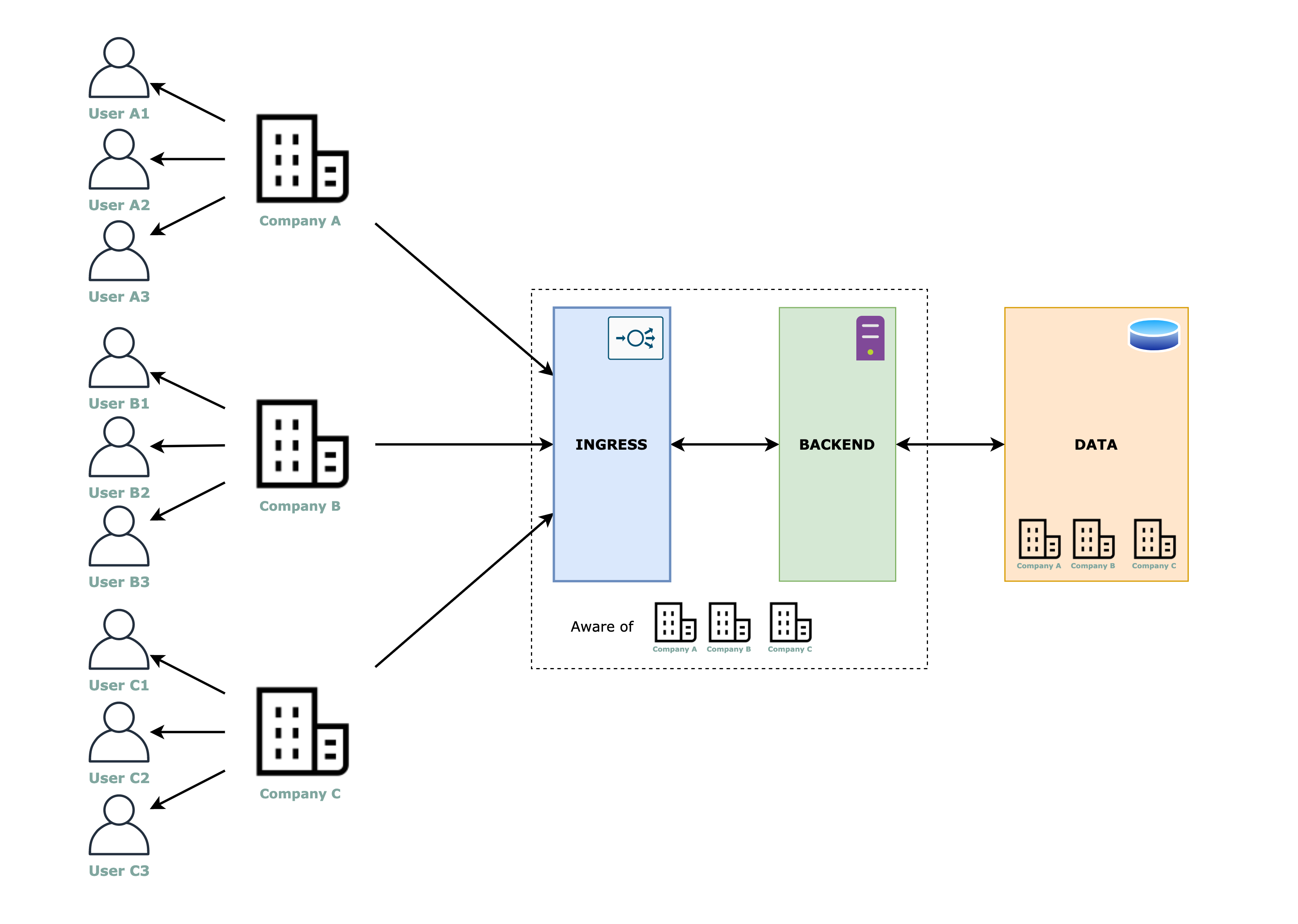
When we say tenant aware, we are saying that the application contains the logic for splitting the traffic/data between tenants. So, for example, based on subdomains or using a login form with a “tenant Id” field (any parameter that identifies the tenant) the application contains code that is aware of from which tenant the request is coming from.
Ingress, backend and data layers
For this approach, the ingress layer and the backend layer are the same for all tenants. The important separation has to be done in the code (as we discussed above) and for the data storage we have mainly 2 options:
- Single database – shared schema or multiple schemas
- Multiple databases
Cloud Infra and Security
The multi-tenancy is achieved in a hybrid manner, part of the work is done by the infrastructure and the other part is done at the application itself. The cloud part is easily achievable here, you just need a scalable ingress, backend, and database.
It is a good option when your application is going to be built mostly on serverless services, like cloud functions/lambdas or app engine/beanstalk. In this case, the ingress and backend infrastructure is managed by your cloud provider. For the data layer, either option you choose (single DB vs multiple DB) you will have to come up with some automation to create new tenants.
Product compatibility. When to choose it?
The main infrastructure is unique and shared between tenants therefore it is cheap. It allows you to scale down to the lowest amount of resources possible, thus saving money.
It’s a great choice for products that will have thousands, millions of tenants. Generally, those products are not expensive for the tenants. Let me give you an example… imagine a cloud email app. Thousands of companies will pay a little money for it.
When using the “tenant-aware” architecture, making sure your code is good and your tenants are properly isolated becomes a priority. By no means you want to have problems with mixed data or causing cross issues between two different tenants.
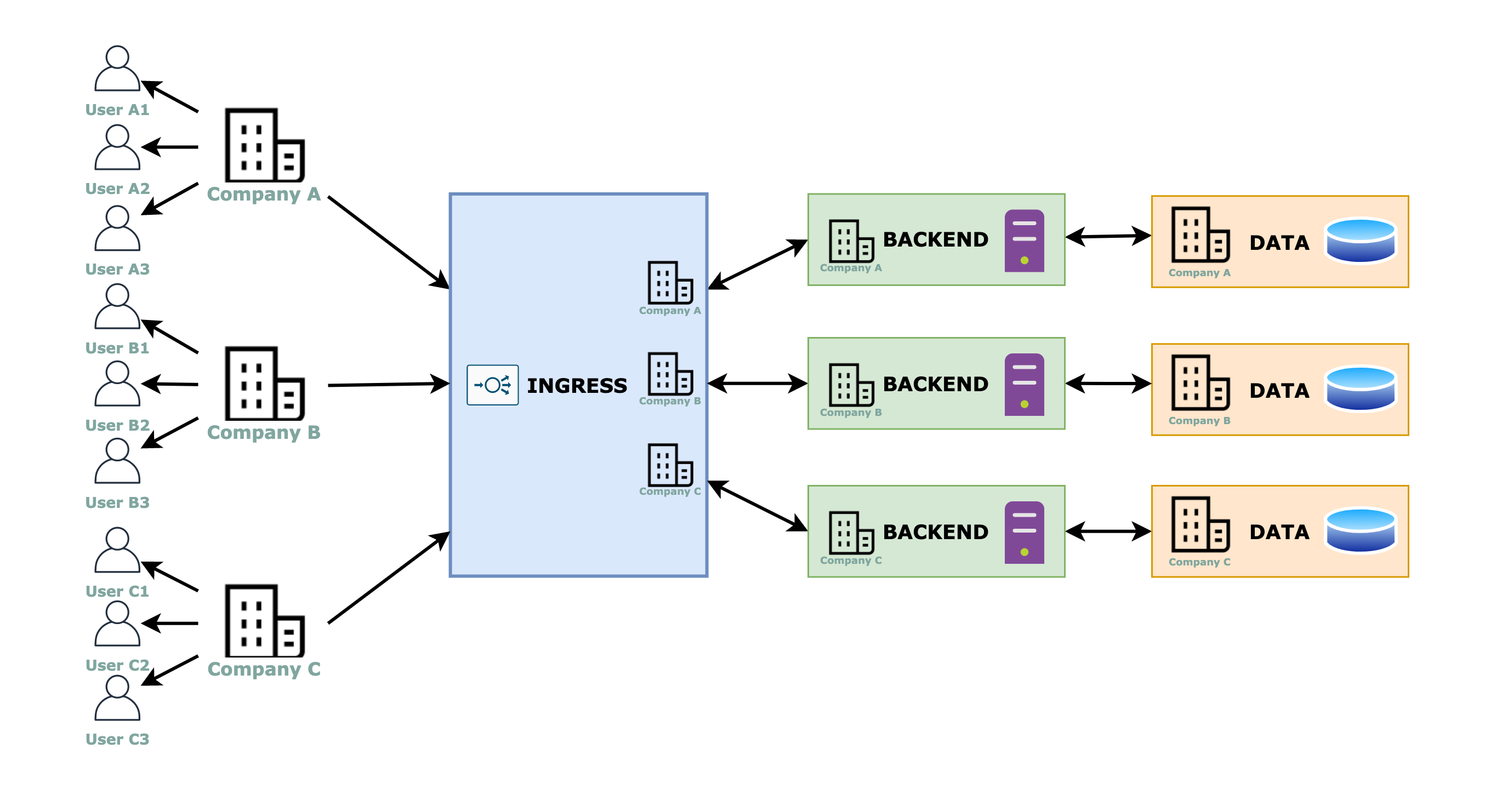
Approach #2: replicated workloads

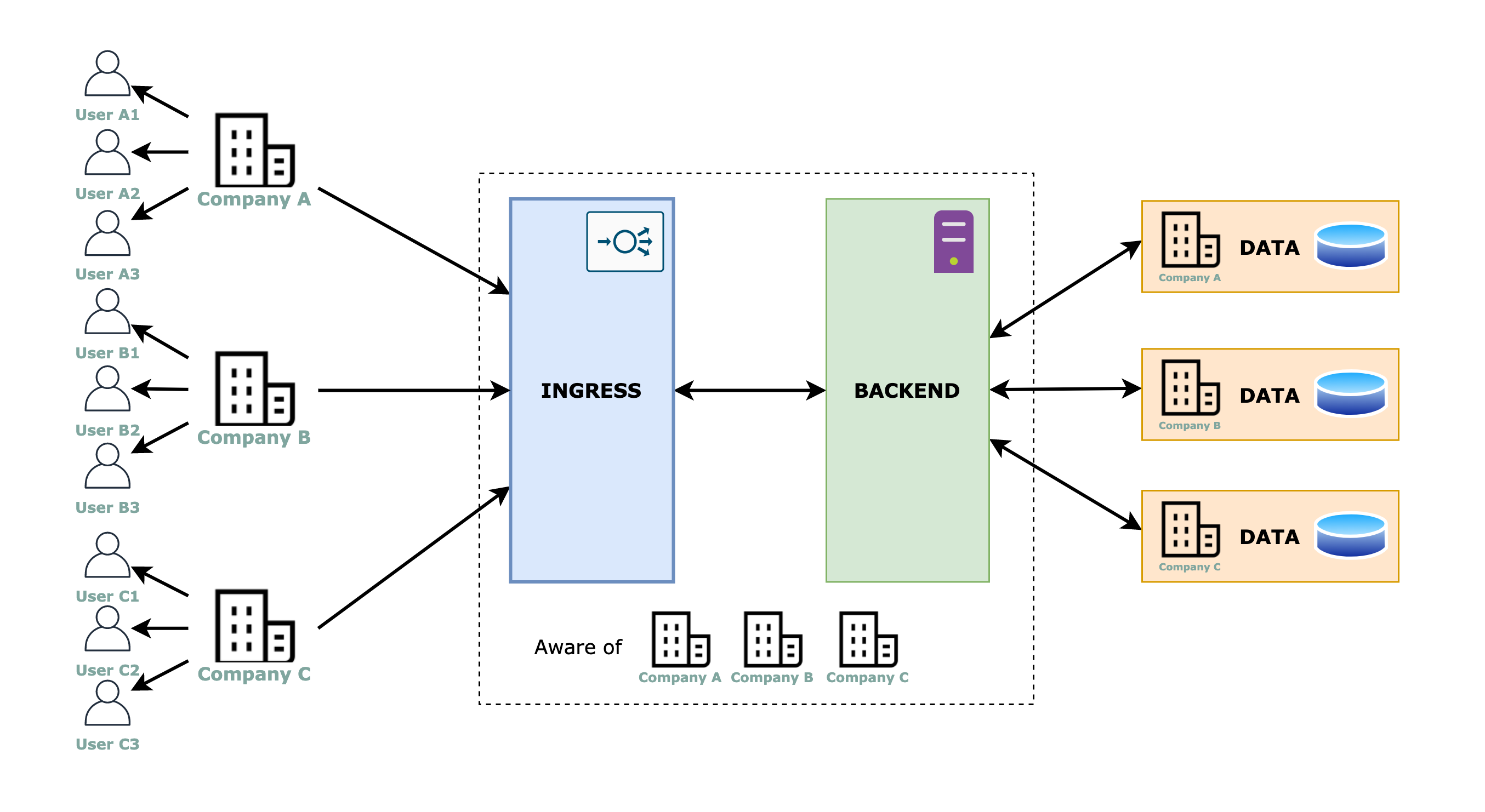
For this approach, the multi-tenancy is resolved completely at the infrastructure level, therefore, the code for each tenant is not aware of any multi-tenant capabilities.
Ingress, backend and data layers
The ingress can be multiple ingresses (above image) or a single one (below image) that reroutes the traffic based on subdomains or paths in the URL, or any other tenant identifier field that a “smart” load balancer can detect, for example, the AWS Application Load Balancer can redirect the traffic based on a header value.
The decision either to choose one ingress vs multiple ingresses comes with some tradeoffs too.
If you have a single ingress, depending on the type of ingress you design, you may face a scalability issue. For example, if you are using Google Cloud HTTPs Load Balancer as a single entry point, and you have one subdomain per tenant, you will need to double-check your SSL certificates because there is a hard limit of the number of certificates the load balancer can have.
If you go with the multiple ingresses approach, make sure you have everything automated because managing a lot of ingresses will become an issue when the number of tenants raises up.
Cloud Infra and Security
There is a backend and a data layer completely dedicated to each tenant, thus we have completely isolated and therefore more secure environments.
The negative part is that we have more resource usage. Instead of grouping compute resources together, you will have idle resources laying around everywhere. Fortunately, Kubernetes comes to help us here! This is a good approach when you plan to use microservices and/or dockerized workloads. Replicating namespaces and workloads is not “that expensive” with Kubernetes. Of course, you need to think about the data and ingress layers too.
Product compatibility. When to choose it?
The tradeoff is clear, by using this approach, your infrastructure costs more, but probably you do not need to spend a lot of time in making your code “tenant-aware”.
This is a good option when your product is expensive for the customers so you can afford to have a more expensive infrastructure.
Again, if security and isolation are really important, this approach is a must for complying with the standards.
Conclusion
Each architecture has benefits and tradeoffs, but the important takeaway from here is that it is not only a technical decision but it has to be aligned with the expectations from the product side of your SaaS application. How much it will cost to obtain new customers? How much your customers will be willing to pay for your product? is isolation a key?
I hope this post helps you to trigger the right discussions. 🙂