Un Proxy es un servicio que actúa como intermediario entre una comunicación del tipo Cliente-Servidor.
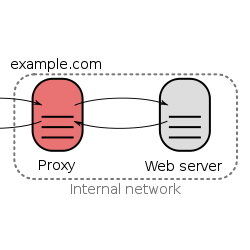
Mientras que un proxy normal (Forward Proxy) hace que un servidor no te contacte directamente, sino que es el proxy quien se conecta con el servidor, manteniendo al cliente en el anonimato, un Reverse Proxy, mantiene al servidor en el anonimato para con sus clientes…
Éstas imágenes lo aclaran muy bien:
Forward Proxy:

Reverse Proxy:
(Gracias Wikipedia por las imágenes)
Para qué podemos utilizar un Reverse Proxy?
Los usos son muchos, pero el clásico es el siguiente:
Supongamos que instalamos un servicio en nuestro servidor, este servicio responde al puerto 8080, es decir, accedemos a este servicio mediante http://www.example.com:8080.
Pero queremos acceder al servicio mediante http://servicio.example.com porque es más fácil para los usuarios.
Obviamente, no podemos configurar el puerto del servicio para que use el 80 porque tenemos un Apache o que ya está corriendo en ese puerto…
Entonces, “enmascaramos” la verdadera URL con el Reverse Proxy…
Como configurar un Reverse Proxy en Apache:
Primero instalamos un paquete que nos va a servir:
apt-get-install libapache2-mod-proxy-html
Luego, activamos los módulos de apache:
a2enmod proxy
a2enmod proxy_html
service apache2 restart
Con eso, ya estamos listos para crear el proxy.
Es muy sencillo:
NameVirtualHost *:80 <VirtualHost *:80> ServerName service.example.com ProxyPreserveHost On ProxyRequests Off ProxyPass / http://www.example.com:8080/ ProxyPassReverse / http://www.example.com:8080/ </VirtualHost>
Esas lineas dentro de un Virtual Host de Apache, son suficientes para que el proxy funcione…
Pero, si el servicio que esta detrás del proxy utiliza mucho Ajax/JavaScript/CSS, vamos a notar un rendimiento muy pobre, en otras palabras, si accedemos al sitio desde la URL original: www.example.com:8080 tendremos una respuesta normal, pero si accedemos mediante la URL enmascarada, service.example.com, podemos llegar a tener demoras de 10 a 20 segundos!! inclusive puede ocasionar Time-Outs…
Es decir, un sitio web detrás del Reverse Proxy, se va a notar muy muy lento. Mucho más lento que accediendo desde la URL original.
Esto sucede porque por defecto, el mod_proxy solo re-mapea las URLs en los headers, no en el contenido de la página, además el modulo mod_proxy_html tampoco parsea CSS o JavaScript, entonces las URLs que se encuentran dentro de esos archivos y el contenido de la página, no son re-mapeadas, provocando una serie de Lookups que demoran mucho tiempo…
Entonces, el código final, con lo anterior solucionado sería el siguiente:
NameVirtualHost *:80 <VirtualHost *:80> ServerName sub.example.com ProxyPreserveHost On ProxyRequests Off ProxyPass / http://127.0.0.1:8040/ ProxyPassReverse / http://127.0.0.1:8040/ ProxyHTMLURLMap http://127.0.0.1 / SetOutputFilter proxy-html RequestHeader unset Accept-Encoding </VirtualHost>
Luego, hacemos un último:
service apache2 restart
Y ya estamos listos….
Con eso deberiamos poder acceder a http://service.example.com exactamente igual que si accediéramos por la URL original!!!
Saludos!!


























